Pull: Bahmni event log service
Background
In order to enable users of Android and Chrome app to be able to view and edit data when offline, we would like to synchronise data to their app from Bahmni/OpenMRS. We have divided this data in 3 categories –
- Transactional data – patient and encounters -stored on device
- Reference data – served on device by stored locally (as request URL and response map) in device (by nature small ~ less than 20 items)
- Reference data – stored on device. This will normally have schema offline.
(The distinction between the 2 reference data (2. and 3.) can be made with the help of examples. EncounterTypes can be fetched from definite/static http endpoint that can be remembered, stored locally on device, and future requests will be served from localDB; as there are not many EncounterTypes. However, AddressHierarchy is different beast, we may have upto 5000 entries for address hierarchy for the app, also the endpoint is fluid – its response is based on a search query. In order to facilitate use of such data (others that come to mind – diseases, drugs etc) we would like to store this type of data on the device and serve it from there.)
Technical Constraints
When working with remote devices – esp. tabs we are constrained by the following –
- Network – we would be catering to devices on intermittent at best 2G networks.
- Disk space – devices are very low on disk space.
- Interaction Design for data sync
- Battery
Looking at the above, the design is as follows
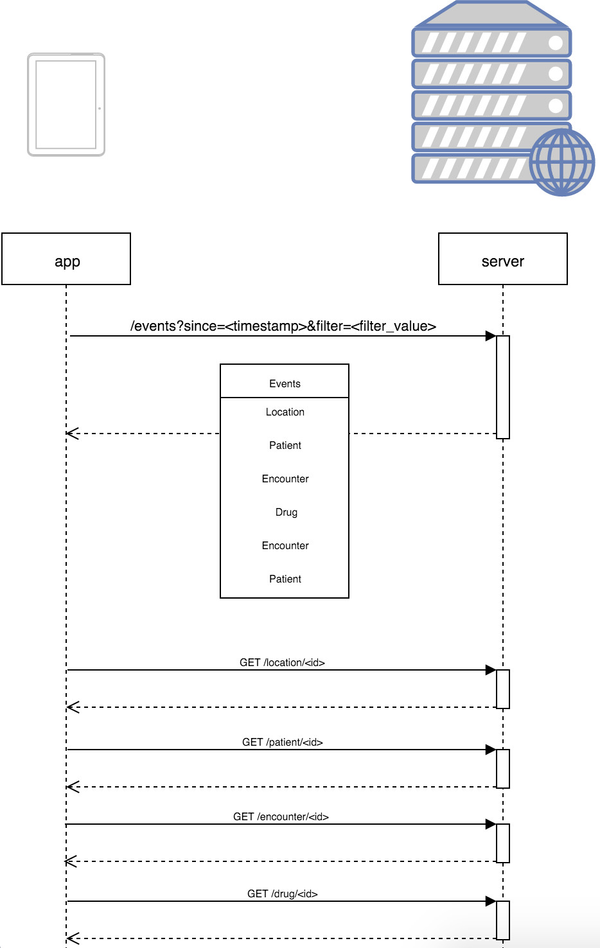
As the diagram above shows –
- the first interaction with the server would be to get a list of events to be replayed on the app
- subsequent interactions would be to get individual entities from the relevant openmrs/bahmni endpoints, keeping in mind that because of slow intermittent network we need the response sizes to be smaller.
The is a single marker (the last successful sync id) for syncing all data from the server, as against keeping markers for different entities, which adds complexity. This is based on the fact that transaction data that refers to reference data cannot be created on the server if the relevant reference data is not created first.
Filters
As disk space is one of the major limitations for offline storage, we have filters for the data pulled and stored in device. Here are the list of filters supported to pull the data. Filters works this way: say we have location as the filter type, on login when CHW selects this location. All the patients and related data are filtered based on this location and stored it the device locally – this way, we can make sure the low powered devices won't run out of space.
Event Log
In order for the bahmni server to respond with events that depict create/update of entities (transactional and reference), we would store the events in a new table called event_log. As of now, the event_records table keeps timely records of create/update of transactional entities and some reference data entities. However, we should avoid using table because –
- The advice that writes data to this table is in bahmni-atomfeed repository, which is generic in nature and caters to atomfeeds only.
- To add some attributes to the table to enable filtering by location etc. and update the advice to enter these attributes too
- To enter events pertaining to reference data that has not been covered in the atom feeds till now and back date them.
However, will will use the event_records as a source of events, and in that regard, we would need to add more reference data entities like address hierarchy to the same advice that writes events about transactional data to the event_records table.
We will write a background service that will read data from the event_records table and figure out the filter attributes, and push that data, in temporal order, to the new event_log table. A new service endpoint will be written on the lines of the diagram above.
The event_log table should have the following attributes –
- event id
- category (same as in event_records table)
- link to the entity for GET calls
- time of create/update event (as is from event_records)
- filter (for BD, this would be location that the transactional data belongs to)
Push:
Offline syncBahmni Connect sync from device to server
Once the device goes offline, we have all the required patient and clinical data already present in the localDB (lovefield or SQLite) through the event-log-service pull. The chromium app or android app will behave like "offline first application", which means any data read or write happens to localDB first and will be synced to the server later. The sync is based on the sync cycle, which is configurable.
There are two syncs required for offline appsfor Bahmni Connect are:
- From server to device: server to device sync is defined as part of event-log-service, which is defined here. For e.g: Any patients existing in server are filtered and synced to the device by the CHWs' location.
- From device to server: And data created are edited in the device are synced back to server. For e.g: Any patients edited or created on the device are synced back to the server. This process is described here.
Resetting the session cookie
Since the chances of device being offline for more time than the server timeout, all the POST requests can fail on sync back to server. So, any exception for 403 (Session timeout), should redirect to login page on the device and stop the push and pull process. The user has to login successfully again to initiate the process.
Local Database and EventQueue
The localDB stores the data as documents in the device. If edit e1 happened to the document, followed by edits e2, e3, e4, e5. These events are stored in the event_queue. When e1 is synced, it will fetch the latest document from localDB and push to the server. Further events for e2, e3, e4, e5 will try to push the same latest changes and since most of our events are idempotent, it would not fail – we are not optimizing this as of now. The flow looks like this:
- e1 represents edit to patient 1, the patient data in localDB is the edited 1; also there is an event e1 pushed to queue.
- e2 represents another edit to patient 1, the patient data in localDB is replaced with e2; also there is an event e2 pushed to queue.
- The same thing continues till e5. Now the localDB has patient data as <edit 5>, event queue <e1, e2, e3, e4, e5>.
- The sync to server starts and pulls e1 from event queue, and sees the patient id and pulls the data from local DB which is <edit 5>. It posts the request and on success removes the event e1 from event queue and patient data is <edit 5>. In case of error which is of specified error type, e1 moves to error_queue.
- Steps c and d happens with e2, e3, e4, and e5. Since the requests are idempotent, these requests may not fail.
Right now the event_queue is hustle. We will have two queues:
- event_queue: This contains list of all the events that has to be synced to the server. For example, if Patient p1 has edits p1e1, p1e2, p1e3; Patient p2 is created p2e1; Patient p1 is edited p1e4 – the event queue looks like p1e1, p1e2, p1e3, p2e1, p1e4.
- error_queue: The events in the event_queue are pushed to the server and in case of errors like 5xx or 4xx, we move these events to the error_queue. The max errors in the error_queue should be configurable. Once the number of errors increase, the push and pull should stop and wait for manual fix.
Error types that pushes events to error_queue
Which pushing the events from event_queue to server, if there are any of the following errors, they will be pushed to the error_queue.
- 5xx:The server failed to fulfill an apparently valid request.
- Server is down
Data states and push
Let us use the example of patient data. In the device the patient data can be in three states:
- New patients created in device and not present in server: We need to push these changes to the server. There wont be any conflicts , since these are new patient data.
- Patients that were synced from server, but edited in the device, and changes not yet synced back to server: We need to push these changes to the server.
- Merge conflicts: But there maybe rare chances of changes to that patient data in the server. The approach right now is the push and override the changes.
- Push failures: There are chances that the push gives us 5xx error and cannot be retried. This is elaborated in detail below.
- Patients data that are same in device and server: We need not worry about this for obvious reasons.
1. New patients created in device:

2. Patients that were synced from server, but edited in the device

For the patients that were synced from server and edited in offline mode, following are the scenarios:
- Edit the existing patient when offline: Each edit of the patient will update the local database and also add an event to the event_queue.
Edit the existing patient multiple times when offline.
Pull and Push: Scheduler
The push and pull of events will go through common configurable scheduler. The scheduler is a job that runs in background. The scheduler has a set of workers. And these workers run as stages/steps. Workers are executed in the order they are staged in the job – they run one after the other. Each task that the worker execute is async and does not block the stages. But each stage executes only after the previous stage executes successfully. The reason for only one job, is to drive the single configuration for app.
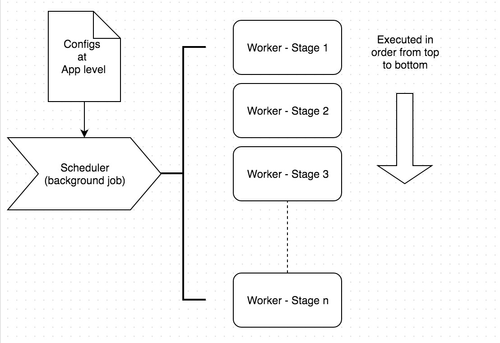
Workers can be in 2 states:
- started: The workers execute methods is running.
- stopped: The worker is done executing or stopped because of some error.
Workers may go into sleep, if there are any acceptable errors (not these). When the scheduler wakes up, it will start the stages from the beginning. It means workers should be designed to run idempotent tasks. And if the device is offline for acceptable errors, the scheduler will retry:
- after the configured wait time or
- the sync button is clicked in the app
The design is right now "push first", which means the scheduler tries to push all the changes from the device first and then tries to pull changes from the server. So as of now the push scheduler need not worry about the merge conflicts. Even in the push, first error_queue will be tried once to be pushed and then event_queue will be tried.
Pull and Push: Scheduler order
Initial setup:
- Pull configs
- Pull small reference data like global properties and rest calls data. E.g: Login locations, genders
- Pull transactional data from event log service post successful login. E.g: Patients
Background process:
- Pull configs
- Pull small reference data like global properties and rest calls data. E.g: Login locations, genders
- Push error_queue
- Push event_queue
- Pull transactional data from event log service post successful login. E.g: Patients
Pull and Push: Errors
Pull errors can happen on:
- Lost packets: Will be automatically handled by TCP.
- Device memory is full: requires manual fix.
- Event log service is down/not reachable: Should manually restart event log service.
- If the error happens in saving the data to local database then the transaction will be rolled back.
Push errors:
- 5xx: The event moves to the error_queue (if error_queue is not full).
- Other https errors: The scheduler will go to sleep till starts back after the configured time or the sync button is clicked.
Pull and Push through sync button:
Sync task will be running periodically based on the time interval that is configured.As soon as the sync process starts background process will be triggered. If there is any problem in the background process or if the configured time interval is too long, in between user can start the sync process by manually clicking on the sync button which is available in all the modules.Sync button is available for chrome extension and android app. As soon as the user clicks on the sync button scheduler will be started in the background. While the sync is in progress image with loading symbol will be shown. After sync is done sync button is available again to manually start the sync process.
Device errors
The device can have following errors:
- Out of memory: In android, the device can run out of memory and Bahmni app cannot save or sometimes sync data. User has to manually clear of the unnecessary files and trigger the sync.
- Password of user changed in server: The user has to successfully login again when online.
- Wrong build with sync issues deployed in device: A update of the app will change the files in the bundle with the latest. So it should fix the issue. In rare cases, the user has to re-install the app, and all the data in the device is lost.
- SD card issues: In android, where SQLite is configured as storage; sometimes SD cards fail. User has to manually try recover the data, otherwise the data is lost.
- Application crash: Bahmni app can sometimes crash – both in chrome and android. We don't lose the data on crash.
Pulling Concepts for
offline device fromBahmni Connect from server.
When a concept is added to Offline Concepts concept set or a concept is modified which is set member of Offline Concepts, an event is generated in event_records table in openmrs, the same entry which is generated in event_records table is then copied to event-logs table. As soon as the sync start we copy the event from event_log to our offline database.
Implementers Configuration:
- Add Bahmni Offline Sync Omod in openmrs modules
- Add the concepts which Offline app needs Bahmni Connect needs to "Offline Concepts" concept set.
| Panel | ||||||
|---|---|---|---|---|---|---|
| ||||||
|